A Multi-Faceted Taxonomy
Two base settings, seven derived settings, and extensions to other modalities — showing how assumptions reshape the problem.
Zhenqi He,
Yuanpei Liu,
Kai Han
Visual AI Lab,
The University of Hong Kong
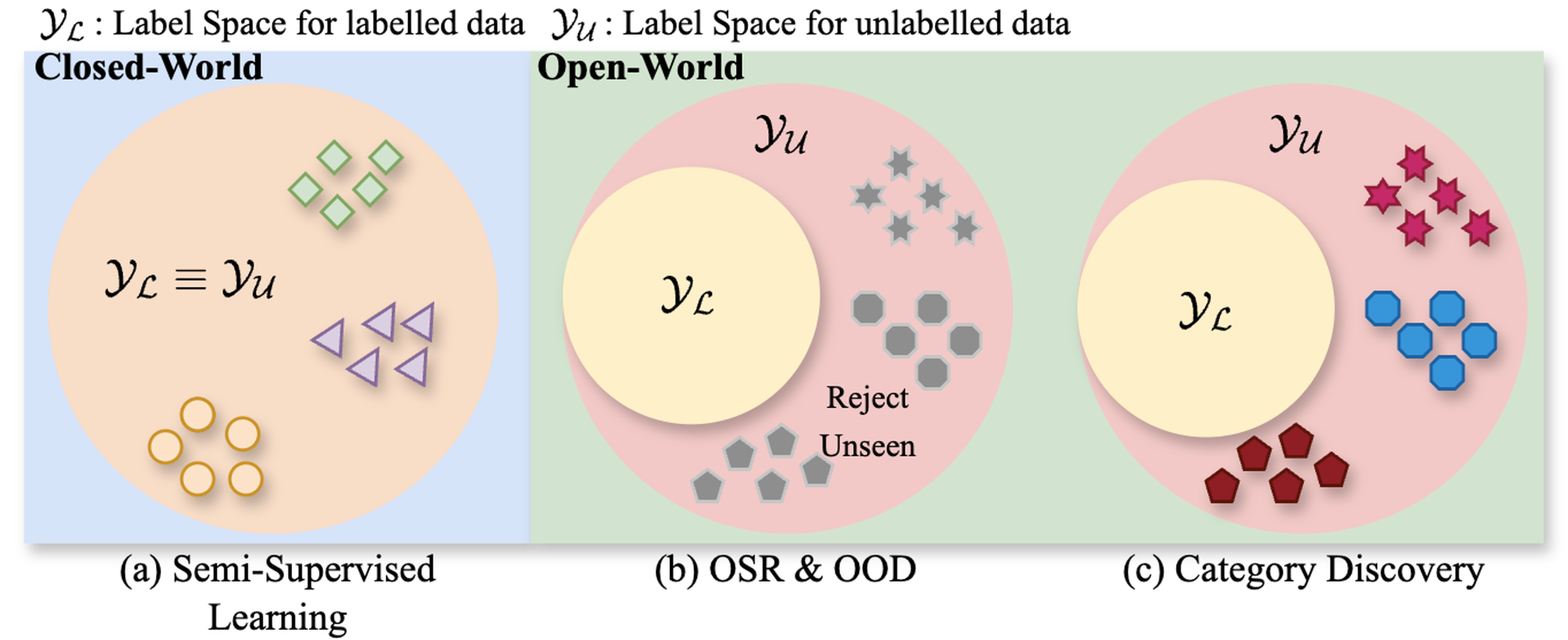
Category Discovery groups unlabelled data into meaningful categories, guided by labelled known classes. Unlike semi-supervised learning, it assumes no fixed label space; unlike open-set or OOD detection, it discovers the structure of unknowns rather than just rejecting them. This work summarises and analyses the field's settings, methods, benchmarks, and open challenges from an open-world perspective.
Category discovery moves fast. We maintain an open, continuously updated repository of papers, benchmarks, and code — and it grows with the community. Spotted a new paper or a missing reference? Open a pull request and add it.
A map of the field — from problem definitions to open-world scenarios and standardized benchmarks.
Two base settings, seven derived settings, and extensions to other modalities — showing how assumptions reshape the problem.
Every method reduces to three components: representation learning, label assignment, and class-number estimation.
NCD and GCD compared on generic and fine-grained datasets, with consistent backbones, splits, and protocols.
What works today, and the key gaps to close before reliable open-world discovery.
No single axis captures the field. We separate label-space assumptions, deployment challenges, and data modalities.
Cluster an unlabelled set of only unseen categories, transferring knowledge from labelled base classes.
YL ∩ YU = ∅Cluster unlabelled data mixing seen and unseen categories — more realistic, but biased toward labelled classes.
YL ∩ YU ≠ ∅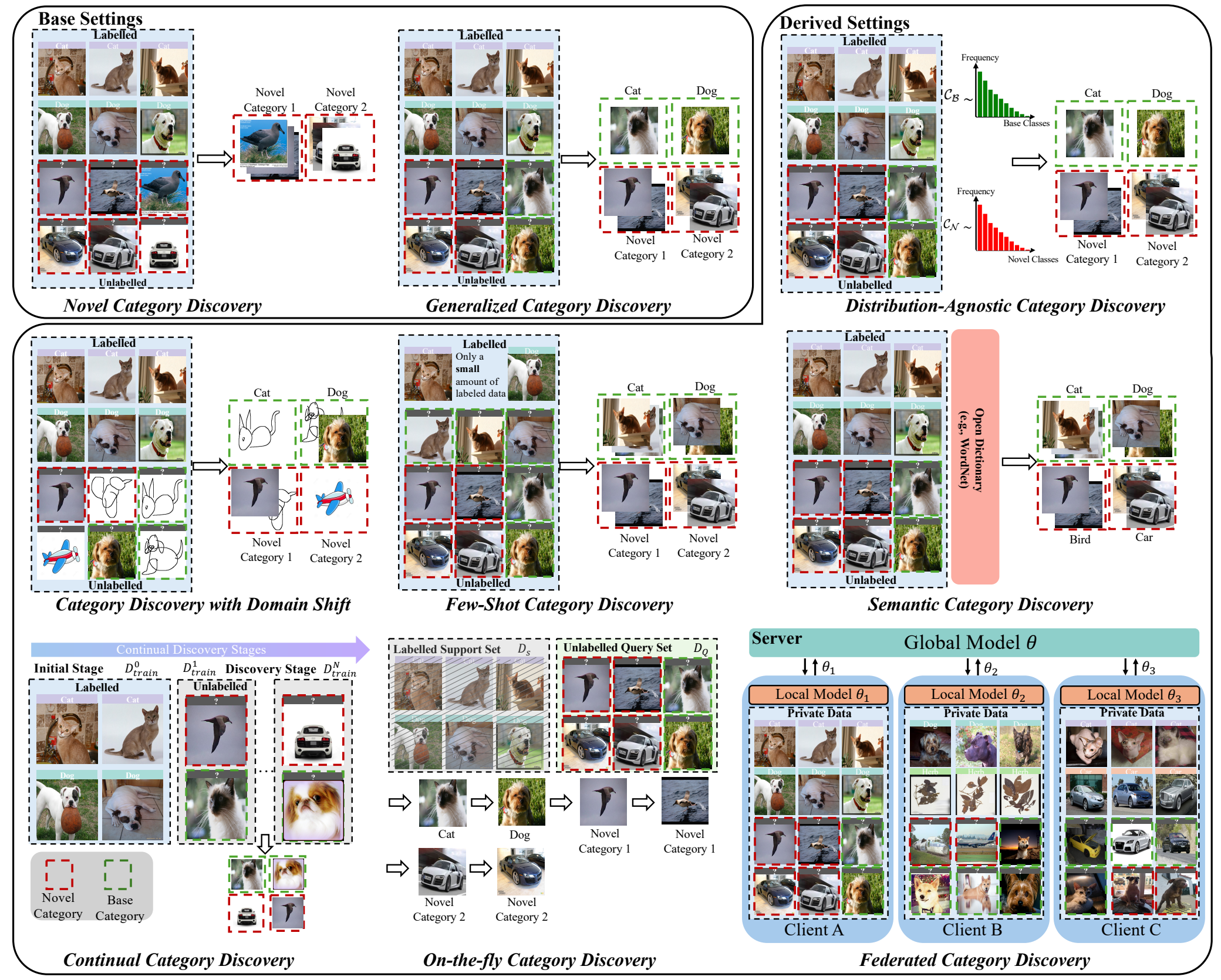
The taxonomy across two base settings and seven derived settings.
@article{he2026category,
title={Category Discovery: An Open-World Perspective},
author={He, Zhenqi and Liu, Yuanpei and Han, Kai},
journal={arXiv preprint arXiv:2509.22542},
year={2026},
url={https://arxiv.org/abs/2509.22542}
}