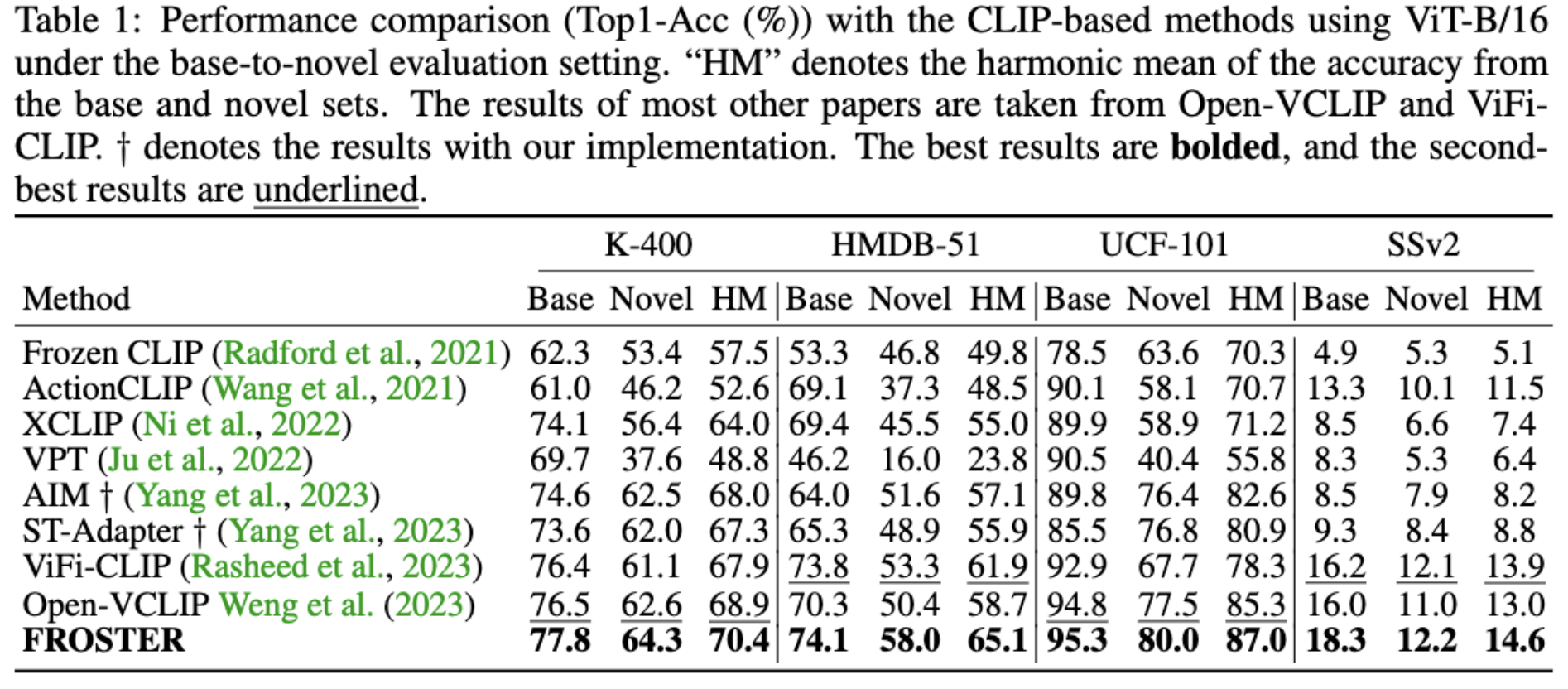
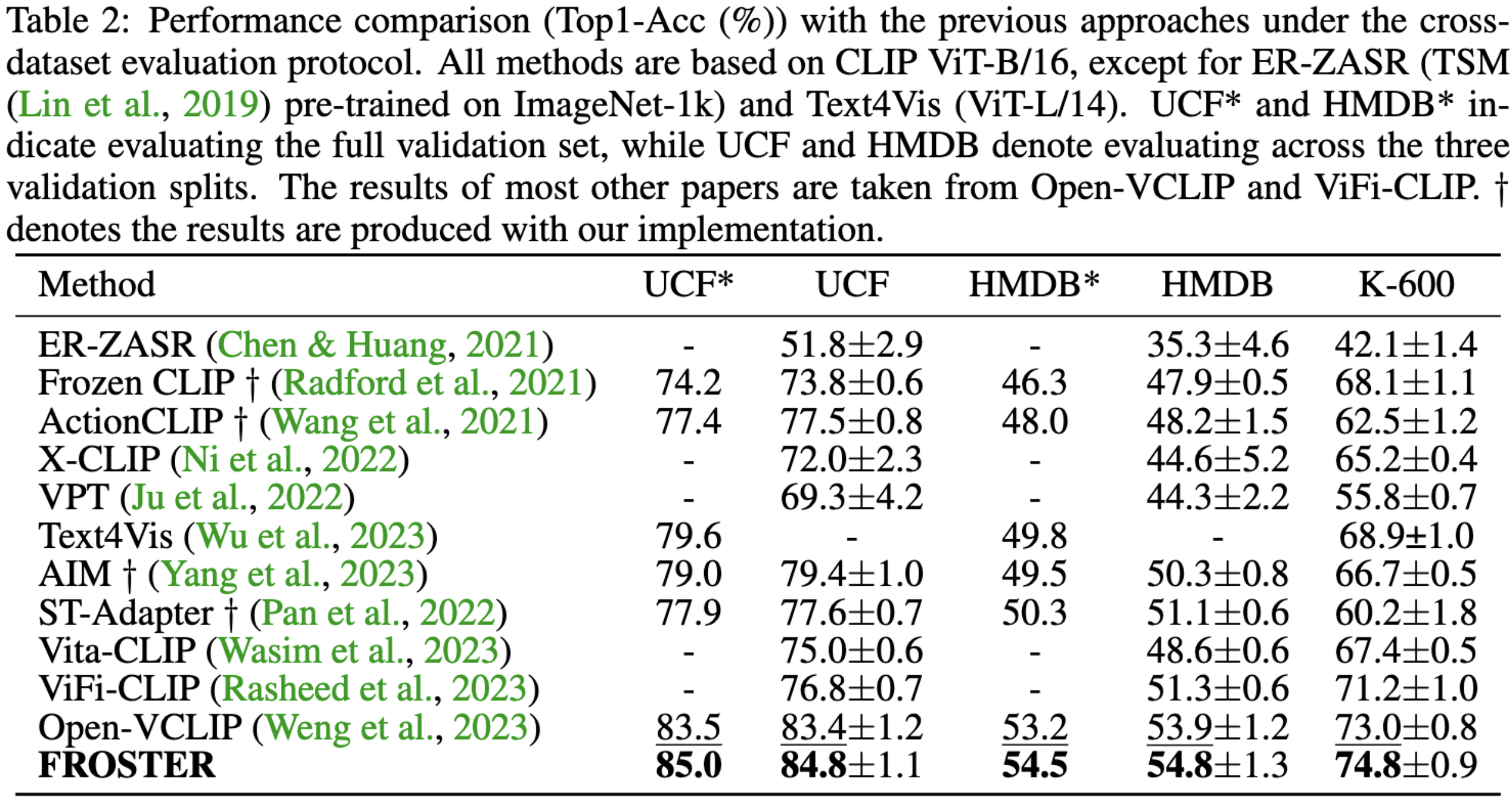
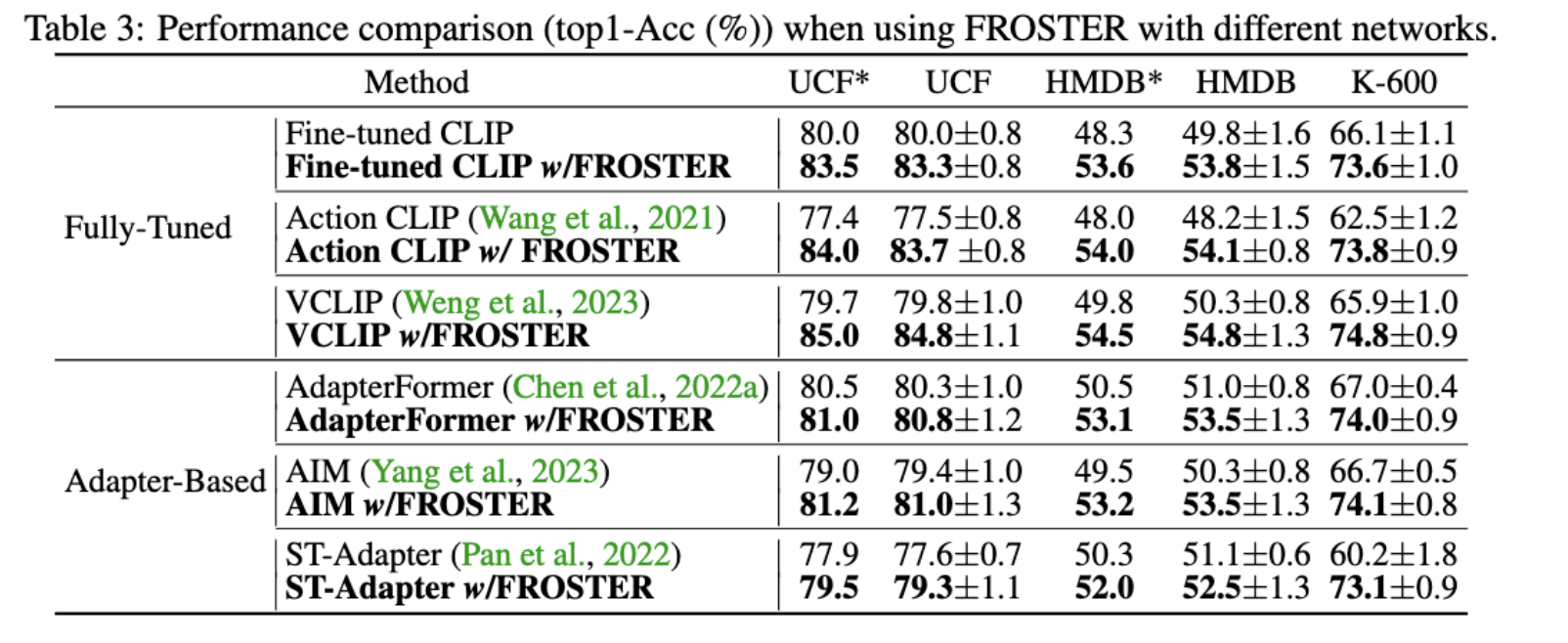



General Pipeline
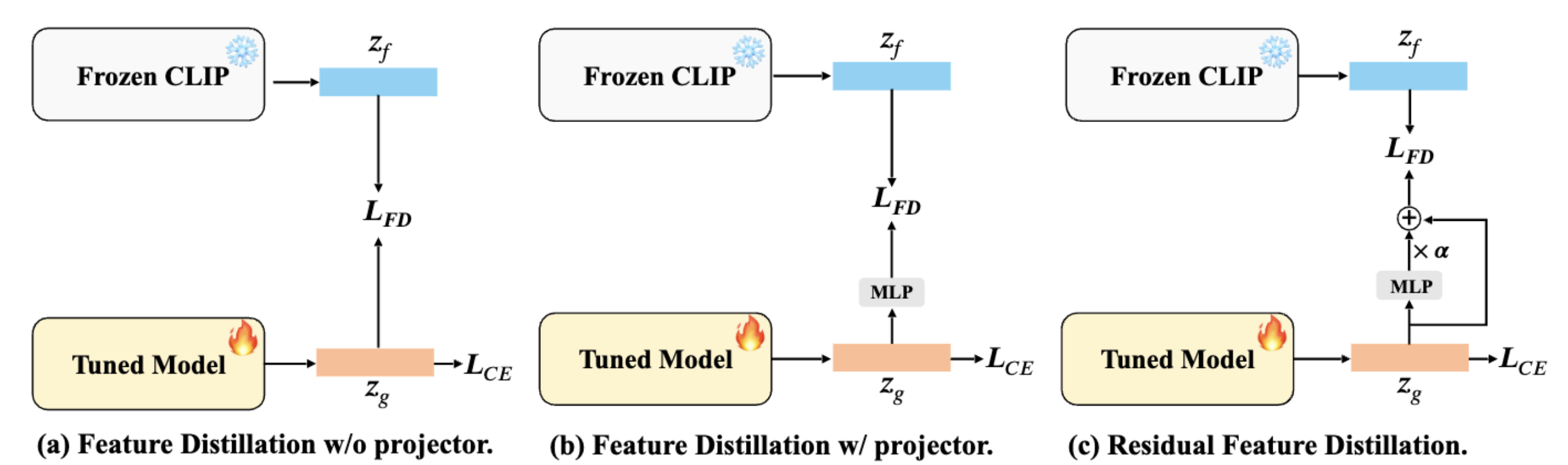
The overall pipeline of FROSTER consists of two key components, namely, model finetuning to bridge the gap between image and video tasks, and knowledge distillation to maintain the generalizability of the pretrained CLIP.
As shown above, "video-specific" is achieved through common classification-based finetuning, while `generalizable' is achieved by using frozen CLIP as a teacher to impart pretrained knowledge to the tuned model, inspired by knowledge distillation techniques, which involves using frozen CLIP as a teacher to impart pretrained knowledge to the tuned model.
The distillation process is akin to a regularization term that ensures the tuned features do not diverge too far from the frozen ones. To balance the feature learning between the two distinct goals, we propose a modified residual network for conducting distillation. The intuition behind the design is to allow the tuned features to effectively receive supervision from generalized ones while also being video-specific.