Abstract
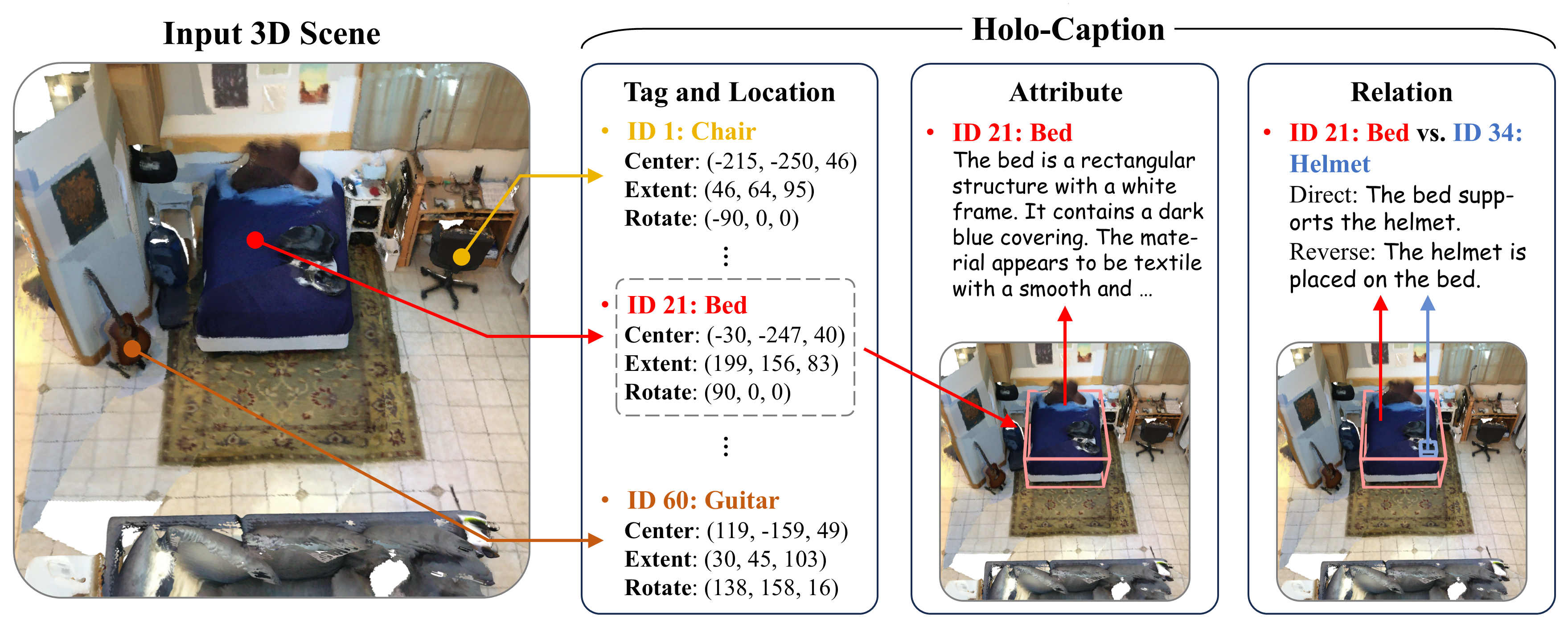
This work introduces holo-captioning, a novel task that strives to seek the text equivalent of 3D scenes. As an initial step, we formulate holo-captioning as generating a structured textual description that comprehensively depicts all entities within a 3D scene, including their semantic tags, spatial locations, attributes, and inter-entity relations.
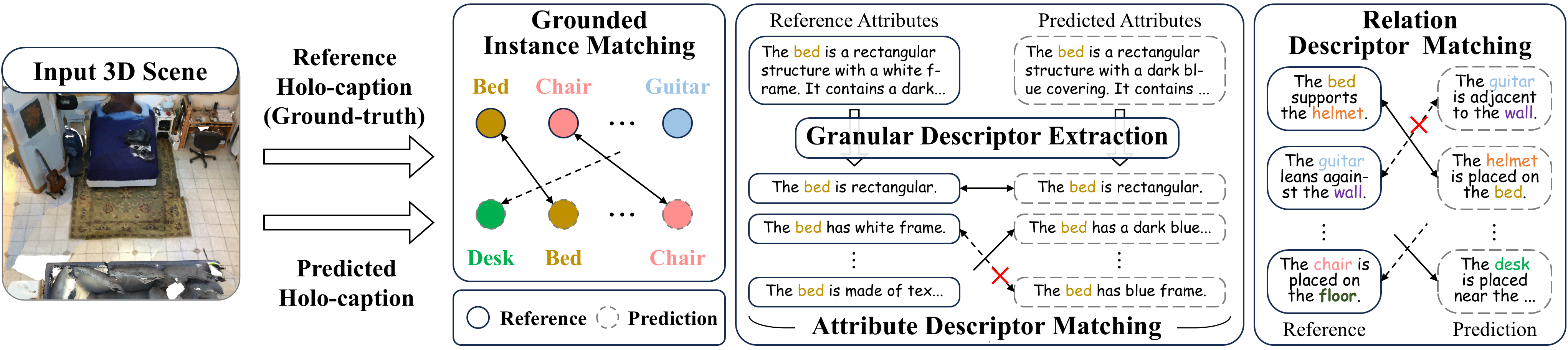
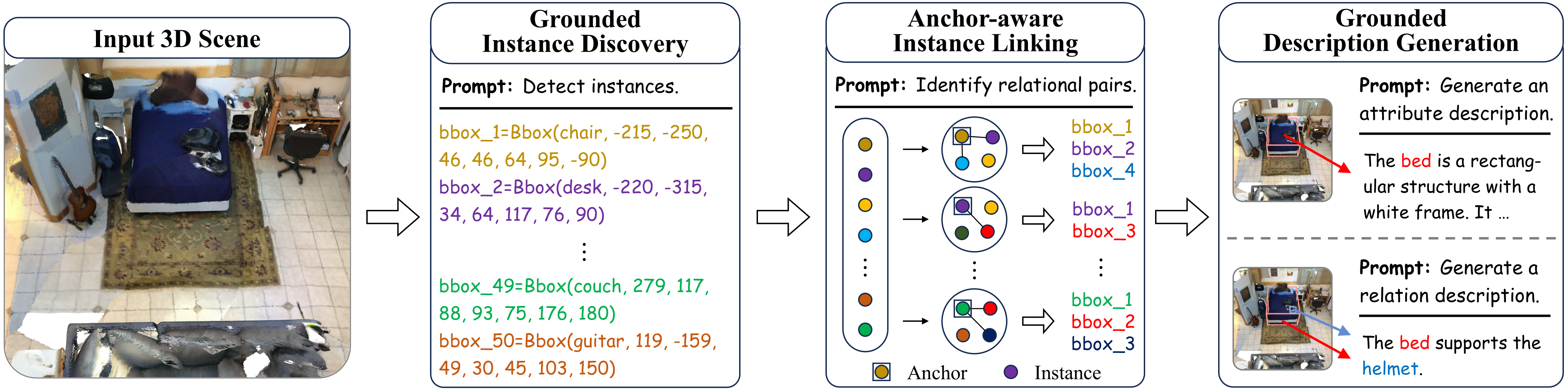
To tackle this challenging task, we develop HoloEngine, an effective captioning engine for producing detailed descriptions of individual entity instances and instance pairs, and contribute HoloScan, a large-scale benchmark comprising over 15K scenes for training and evaluation. Building upon this foundation, we propose HoloScribe, a model with an instance-aware decoupled pipeline for generating structured holo-captions, together with anchor-aware instance linking for relational instance pairs. We further introduce HoloScore, a comprehensive metric with a human-curated test set for reliable assessment. Experiments show that HoloScribe significantly outperforms state-of-the-art 3D dense captioners and 3D LLM generalists.
Our contributions are listed as follows:
- We introduce the novel task of holo-captioning, which strives to seek the textual equivalent of 3D scenes. We formulate it as generating comprehensive structured textual descriptions that cover four fundamental dimensions, and contribute a reliable metric named HoloScore for evaluation.
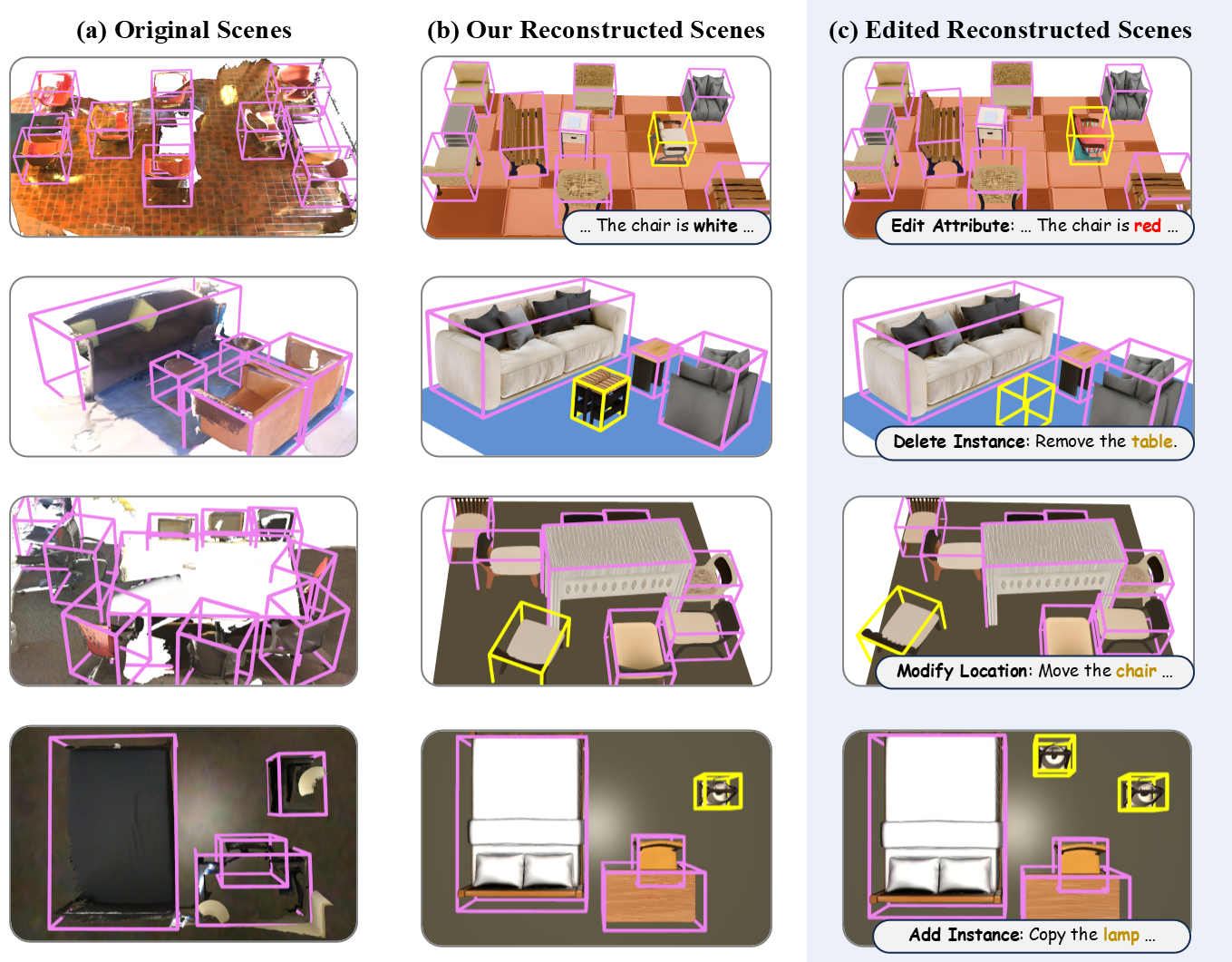
- We propose an effective instance-centric captioning engine named HoloEngine to produce high-quality holo-captions, and contribute HoloScan, a large-scale benchmark of over 15K indoor scenes spanning diverse categories for training and evaluation.
- We propose HoloScribe, a novel model that follows an instance-aware decoupled pipeline to generate comprehensive textual descriptions element by element. To the best of our knowledge, HoloScribe is the first 3D LLM capable of jointly localizing entity instances and generating detailed descriptions in pure text form without extra detectors.